| #SAS统计分析 | 您所在的位置:网站首页 › sas univariate过程 › #SAS统计分析 |
#SAS统计分析
|
关于统计性统计的基础概念之前就大致有整理过了,想要回顾的可以点击:
这个主题的文章会侧重于sas关于统计分析的应用的学习整理与讲解,过程中也会补充一些比较重要的统计分析概念。 1. 随机变量及概率分布 在之前的什么总体,个体,样本,简单随机抽样,连续or分类变量,统计量,自由度等概念就不说了,而关于概率分布,我还是再简单提及一下。 1)伯努利试验&二项分布 最简单的随机试验是只有2种试验结果的随机试验,也称之为伯努利试验。我们假设该项试验独立重复地进行了n次,那么就称这一系列重复独立的随机试验为n重伯努利试验,或称为伯努利概型。
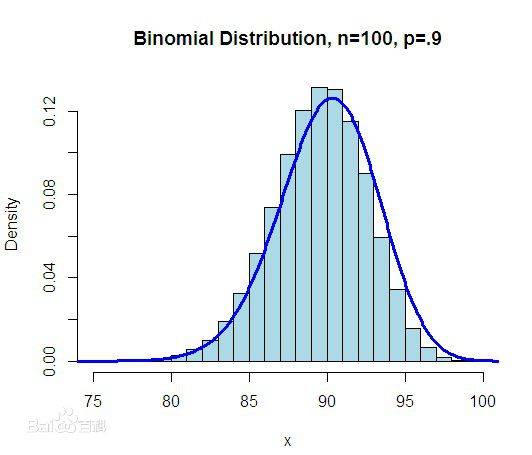
二项分布就是重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变,则这一系列试验总称为n重伯努利实验,当试验次数为1时,二项分布服从0-1分布。 一般地,在n次独立重复试验中,用ξ表示事件A发生的次数,如果事件发生的概率是p,则不发生的概率 q=1-p,N次独立重复试验中发生k次的概率是:P(ξ=K)= (K=0,1,2,3,…n),那么就说ξ服从二项分布,其中P称为成功概率,记作:ξ~B(n,p)。 (1)二项分布的期望:Eξ=np; (2)二项分布的方差:Dξ=npq。 2)柏松分布(poisson distribution) 柏松分布常用来描述单位时间内随机事件发生的次数,是一种统计与概率学里常见到的离散机率分布(discrete probability distribution) 泊松分布的概率函数为:
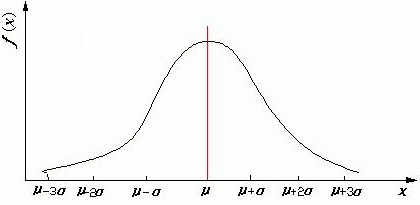
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生率。 泊松分布适合于描述单位时间内随机事件发生的次数,泊松分布的期望和方差均为 入 。 3)正态分布(normal distribution) 正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution),正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。
正态分布是随机变量X服从数学期望为μ、方差为σ^2的分布,记为N(μ,σ^2)。其第一参数μ是遵从正态分布的随机变量的均值,第二个参数σ2是此随机变量的方差,所以正态分布记作N(μ,σ2 )。 遵从正态分布的随机变量的概率规律为取 μ邻近的值的概率大 ,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。 正态分布的密度函数的特点是:关于μ对称,在μ处达到最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点。当μ = 0,σ = 1时的正态分布是标准正态分布。 2. 描述性统计量 抽取合适的样本后,在利用样本数据对总体进行判断统计之前,有必要对样本数据进行探索。一方面,能及时发现样本数据中的问题,如缺失,异常;另一方面,也可以观测数据的分布情况。 描述性统计量主要分为3类: 1)描述数据集中趋势:如均值,中位数,众数等 2)描述数据离散程度:如方差,标准差,变异系数,极差,四分位数等 3)描述数据分布情况:如偏度系数,峰度系数,百分位数,直方图,箱线图,正态概率图等 以上提及的几个常见的统计量,有些大家都是非常熟悉了,我就总结整理一下可能会比较陌生的统计量吧。(下面的统计量就不分类了) (1)变异系数 变异系数是一种不受单位影响的表示数据离散趋势的指标,特别适合于在两种情况下(各组数据的单位不完全相同时,或者各组数据间的均值相差悬殊时)比较各组间变异程度的大小,一般用CV来表示。 CV=s/x,即标准差与均值之比。当CV值小时,均值代表性就大,反之,均值代表性就不大。 (2)偏度系数&峰度系数 统计量偏度系数(skewness)和峰度系数(kurtosis)正是用来刻画数据的分布状态的,偏度系数是用来描述分布是对称分布还是偏向某一侧,峰度系数是用来描述分布是向中心位置集中还是向两侧集中。 偏度系数:正态分布的偏度系数为0,若小于0,数据分布侧向于数据小的一侧,数据的均值小于中位数,称数据呈负偏态分布或左偏分布;反之,则为正偏态分布或右偏分布。 峰度系数:当峰度系数小于0,称为低峰分布,若分布是对称的,则相比正态分布,数据呈现出“薄尾”,较少的数据分布在两端,称之为薄尾分布;反之,分布称之为尖峰分布,以及厚尾分布。 (3)正态概率图 用于检查一组数据是否服从正态分布的图形,是实际数据与正态分布分位数之间函数关系的散点图。如果一组数据服从或接近正态分布,则正态概率图将会是一条直线。 3.描述性统计量在sas中的实现 1)UNIVARIATE过程 UNIVARIATE过程的基本功能如下: 描述性统计分析,涉及偏度、峰度、分位数的计算,频率表的绘制和变量极端值分析等。 常用统计图形的绘制,包括直方图、概率分布累积图和Q-Q图等。 数据的正态性检验。 在SAS系统中,UNIVARIATE单变量过程的基本格式为: PROC UNIVARIATE [选项] ; BY变量列表; CDFPLOT变量列表 [选项]; CLASS 变量列表; FREQ 变量; HISTOGRAM 变量列表 [选项]; ID 变量; OUTPUT [out=输出数据集名] [统计量关键字=变量名]; QQPLOT 变量列表 [选项]; VAR 变量列表; WEIGHT 变量; 其中: PROC语句用于指定使用UNIVARIATE过程进行描述性统计分析,同时,在该语句后常用的选项介绍如下: DATA=数据集名:指定需要分析的数据集。 PLOT或PLOTS:绘制茎叶图、盒式图和正态概率图。 FREQ:生成频数分布表。 NORMAL:对输入变量进行正态性检验。 BY语句用于指定分组的变量,在组内对数据进行描述性分析。 CDFPLOT语句用于控制概率分布累积图的绘制。 CLASS语句的用法基本同BY语句,用于指定分组的变量。 FREQ语句用于指定代表观测频数的变量。 HISTOGRAM语句用于控制直方图的绘制。 ID语句用于指定数据集中识别观测的变量。 OUTPUT语句用于建立一个新的数据表,存放分析的结果。 QQPLOT语句用于控制Q-Q图的绘制。 VAR语句用于指定UNIVARIATE过程分析的变量。 WEIGHT语句用于指定代表观测权重的变量。 UNIVARIATE 程序内有二十六个统计值: 统计值及对应含义 N 非缺失值个数 NMISS 缺失值个数 NOBS 观察体总数 MEAN 平均数 SUM 变量值的总和 STD 标准差 VAR 变异系数(标准误) SKEWNESS 偏度 KURTOSIS 峰度 SUMWT 所有观察体在 WEIGHT 变量上的总和 MAX 变量的最大值 MIN 变量的最小值 RANGE 最大值减去最小值所得的差 Q3 第三个四分位数 MEDIAN 中位数 (第 50 的百分位数) Q1 第一个四分位数 QRANGE Q3 减去 Q1 之差 P1 第 1 的百分位数 P5 第 5 的百分位数 P10 第 10 的百分位数 P90 第 90 的百分位数 P95 第 95 的百分位数 P99 第 99 的百分位数 MODE 众数如果有不只一个众数取最小值的那一个 SIGNRANK 等级符号检定法 (The Signed Rank Statistic Lehmann 1975) NORMAL 常态分配的检定 (Test Statistic for Normality)若观察体个数少于 51 则采用Shapiro-Wilk 的 W Statistic 的方法检定否则采用用 Kolomogorov 2)MEANS过程 主要功能: The MEANS procedure provides data summarization tools to compute descriptive statistics for variables across all observations and within groups of observations(计算描述性统计量,比如均值方差等,还可以用来做置性区间的计算) 常用用法: calculates descriptive statistics based on moments 计算基于矩的描述性统计量,如均值、方差、标准差、偏度、峰度 estimates quantiles, which includes the median 计算分位数 calculates confidence limits for the mean 计算均值的置性区间 identifies extreme values 极值 performs a t test t检验 基本语法: proc means ; by variable(s); class variable(s) ; freq variable; id variable(s); output ; types request(s); var variable(s); ways list; weight variable; 直接运行 proc means过程时,会对所有数值型变量进行操作,得到各变量的非缺失观测数N,均值MEAN,标准差STD DEV,最大值Max和最小值Min。 常用项: data= (field width)fw= maxdec= missing= noobs noprint NWAY:specifies that the output data set contain only statistics for the observations with the highest _TYPE_ and _WAY_ values,使输出数据集中包含_type_和_way_的最大值
默认输出统计量: std标准差、n观测个数、means均值、min/max cv 变异系数、 stderr标准误即样本均值的方差、 css偏差平方和、vardef自由度,clm双尾置性区间,LCLM左尾置性区间,UCLM右尾置性区间, ALPHA=default0.05 (1-置信度)。
Types语句:规定输出结果的分组类型和顺序,其中的变量一定要在class语句中,和class语句中变量的顺序有关 例如class a b c;则 type () a b a*b c a*c b*c a*b*c的type值分别为0 1 2 3 4 5 6 7,type值决定其输出顺序,不同的type类型有些类似tabulate中的table语句,规定以何种变量为分组类型输出; by语句:必须先排序才能用by语句,by语句进行的分组在输出时会输出两个表,而class不会
var语句:规定需要分析的变量
ID语句:取对应变量的最大值放入数据集;
output语句:规定输出数据集以及要输出的变量
关于sas的统计分析就大概讲这些吧~很多还是要在实战中去实践会学得更快~【阅读原文】可以看到我在网路上看到的一些实例,还挺不错的~~ |

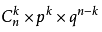
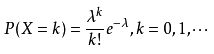

【本文地址】